As agents become more adept at carrying out complex real-world tasks, the methods used to evaluate them must evolve beyond simple measures of accuracy.
Many economically-valuable tasks do not have a single exact answer, but they do have stable expert expectations: domain-specific requirements, procedural constraints, and multiple dimensions of success. That creates a gap between the kinds of tasks organizations care about and the kinds of evals that are easiest to run today.
In our recent paper, we introduce AsymmetryZero, a framework for operationalizing human expert preferences as semantic evals by turning expert requirements into explicit evaluation contracts. Each contract specifies what is being graded, how each criterion is judged, and how criterion-level decisions roll up into a final task outcome. That lets deterministic checks and LLM-as-a-judge criteria live inside the same task schema, with clear audit trails rather than a single opaque score.
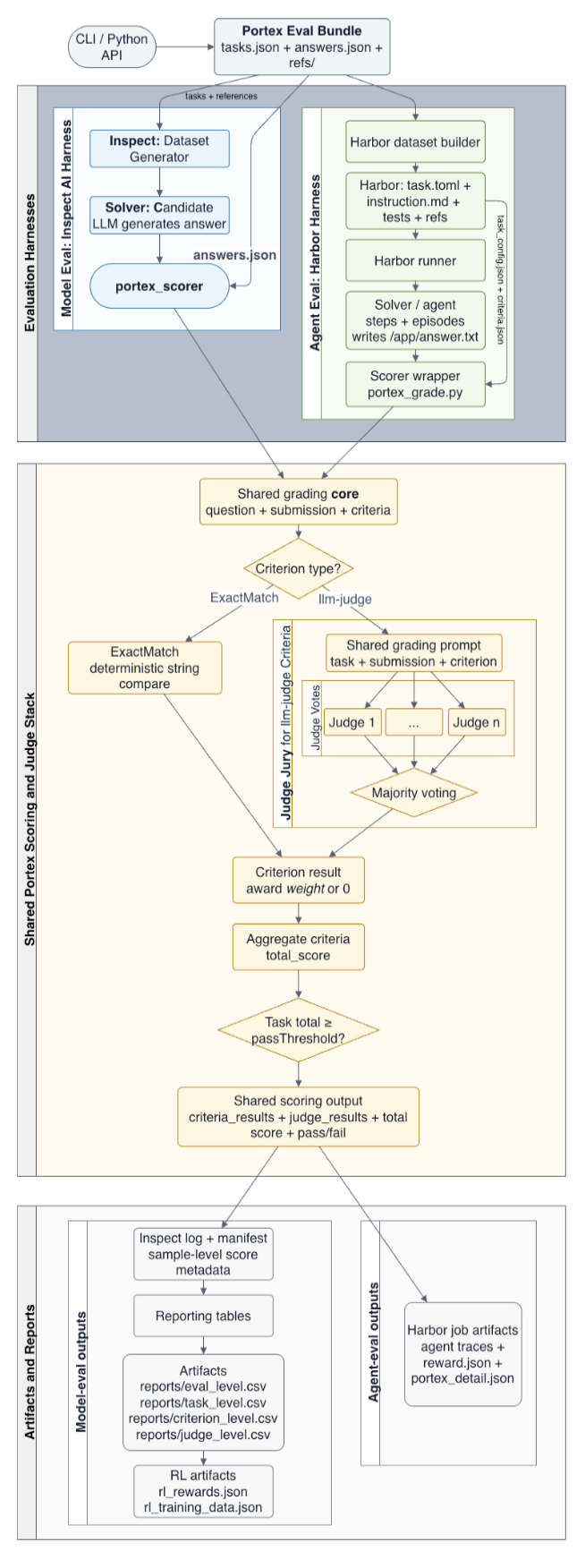
The above architecture diagram makes this concrete. A Portex eval bundle feeds into two execution paths: Inspect for model-only runs and Harbor for agentic runs. But both paths terminate in the same shared grading core. At that stage, each criterion branches by type: either an ExactMatch deterministic compare, or an llm-judge path where a shared grading prompt is evaluated by a jury and resolved via strict majority vote. Those criterion results are then aggregated into a total score and pass/fail outcome, and the system emits shared scoring outputs plus artifacts for downstream reporting and auditing. In other words, AsymmetryZero separates workload execution from evaluation semantics: Inspect and Harbor run different kinds of workloads, while the contract defines what the score actually means.
At Portex, we built this framework for a practical reason. The tasks that matter most in the real economy are often longer-horizon, open-ended, and hard to score with exact match alone. In those settings, evaluation needs to do more than assign a single number. It needs to capture why a system passed or failed, at the level of the rubric itself. AsymmetryZero was designed to support exactly that workflow, with shared evaluation contracts that can run in Inspect for model evals and Harbor for agentic evals.
We're excited to turn this into a practical open source solution as well: we've open sourced an implementation of AsymmetryZero on Github.
We also used the framework to study a key operational question: how much judge capacity is actually needed to run semantic evals well? To answer that, we held the evaluation contract fixed and compared a five-model frontier jury against a five-model compact jury on the same Harbor benchmark runs, across four frontier-class solver backbones.The study used a frontier jury of larger open-weight models and a compact jury of smaller open-weight models, with all prompts, references, criteria, and aggregation rules held constant. Only the judge pool changed.
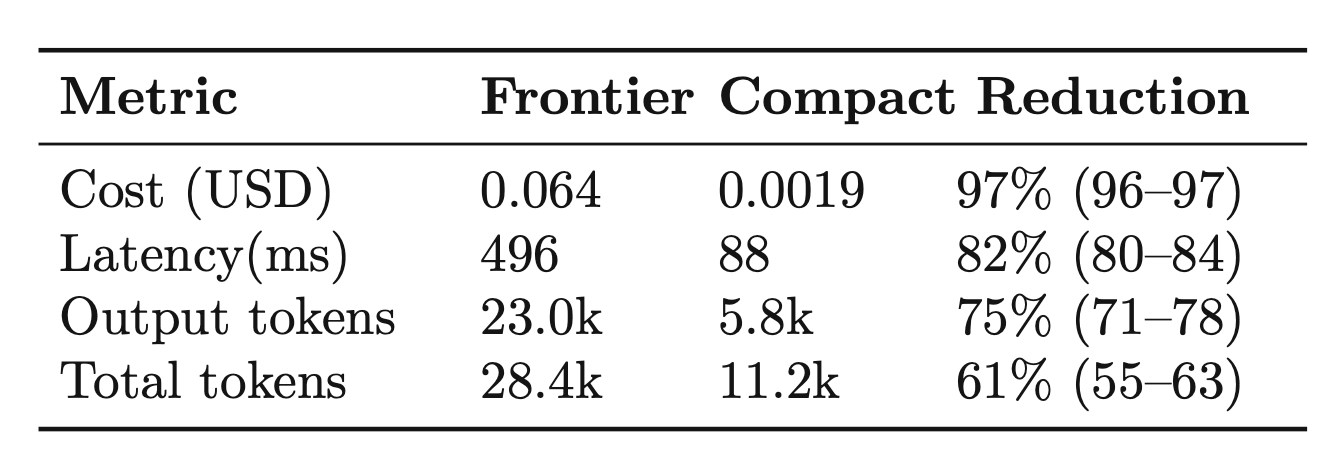
The results show a real tradeoff. On the economics side, compact juries were dramatically cheaper and faster. Averaged across runs, they reduced per-criterion judging cost by 97%, latency by 82%, output tokens by 75%, and total tokens by 61% relative to frontier juries. That is a large operational gain, especially if you want to run semantic evals repeatedly at scale.
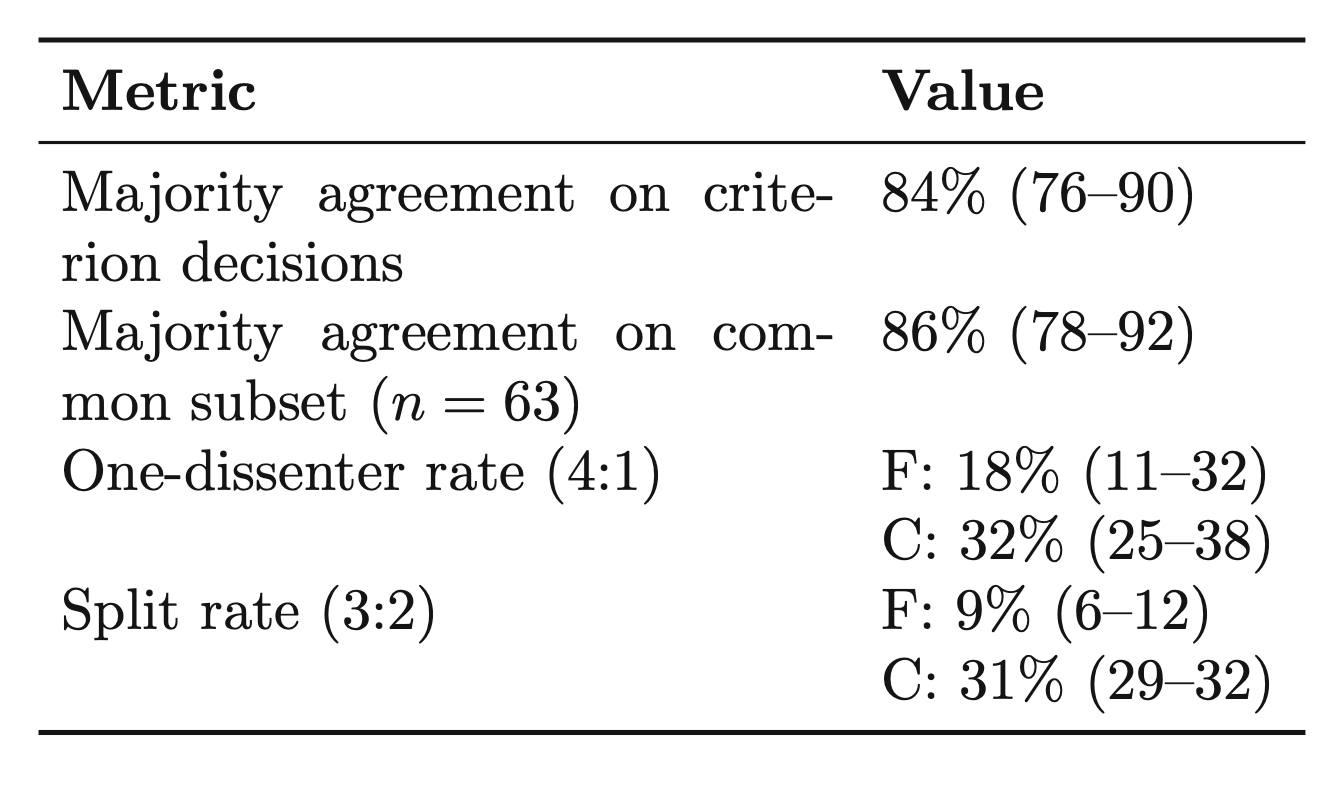
But the agreement results show why cheaper is not the same thing as interchangeable. Across runs, frontier and compact juries agreed on criterion-level decisions about 84% of the time on average, or 86% on the strict common subset. At the same time, compact juries showed much more internal disagreement: frontier juries had a 9% average 3:2 split rate, while compact juries were at 31%; frontier one-dissenter rates averaged 18%, versus 32% for compact. So the issue is not just that compact juries sometimes disagree with frontier juries. They also disagree more with themselves.
That said, many of those criterion-level differences wash out at the task level after aggregation. We find that compact juries often preserve overall task outcomes even when they diverge on individual semantic criteria. That makes them promising for lower-cost outcome monitoring, but not yet strong enough to substitute for frontier juries when criterion-level auditability matters.
That finding points directly to the next area of research for us: post-training compact judge models to better align with stronger frontier juries. A natural next step is on-policy distillation, where trajectories are generated on-policy, labeled by a frontier jury teacher, and used to train smaller evaluator models to reproduce those same criterion-level decisions under a fixed evaluation contract.
As models and agents take on more economically valuable work, evaluation quality becomes part of the product. Our view is that better post-training starts with better eval design: making expert requirements explicit, auditable, and reusable across both models and agents. AsymmetryZero is our effort to push that forward.