We are excited to release COMPOSITE-STEM, a new frontier benchmark testing agents on tasks in physics, chemistry, biology, and mathematics. Agents hold growing promise for accelerating scientific discovery, but measuring that progress requires evaluations that are difficult and realistic. We built COMPOSITE-STEM with Portex domain experts across the sciences to help locate the frontier of agent capabilities.
Spanning 70 realistic tasks from 20 top experts on Portex, COMPOSITE-STEM is the culmination of hours of work and research spent on the Portex Datalab to design frontier evals for the sciences. Our paper, accessible on arXiv, walks through all of the details of task curation and performance across 4 SOTA models. We're also excited to make the benchmark fully open source, with all expert-written tasks and solution rubrics released on Hugging Face below. All tasks are fully Harbor compliant, and we've open sourced a harbor adapter to use COMPOSITE-STEM with this popular agent eval framework.
Over the last few months, we've had the privilege of onboarding over 100 experts across academia and applied R&D to the Portex Datalab. Distinguished faculty members at top global universities, research fellows running frontier wet labs, former physics olympiads—this is just a small sample of the talent using Portex to iterate on agent evals. The datalab has allowed experts to license frontier AI data through a novel product experience and keep their premium evals private. This has resulted in an impressive universe of over 3,000 tasks testing AI agents in dozens of economically-significant domains.
While we are big proponents of fairly rewarding and incentivizing experts for their time, effort, and resources writing frontier evals, the rapid advancement of agents has created a meaningful gap in agent capabilities and the evaluations used to discern where agents excel—and where there are still limitations. Encouraged by the diversity and difficulty of our tasks, especially in the sciences, we were motivated to build a benchmark of the hardest STEM tasks on Portex today to help address this gap. COMPOSITE-STEM was the result of this effort.
Task Composition of COMPOSITE-STEM
The benchmark is composed of 70 tasks, with 20 tasks in Physics, 23 in Chem, 20 in Bio, and 7 in Mathematics.
Tasks in COMPOSITE-STEM require agents to do more than just reason through a difficult textbook problem; they require agents to use tools effectively to analyze, in some cases, novel data that cannot be surfaced from a websearch.
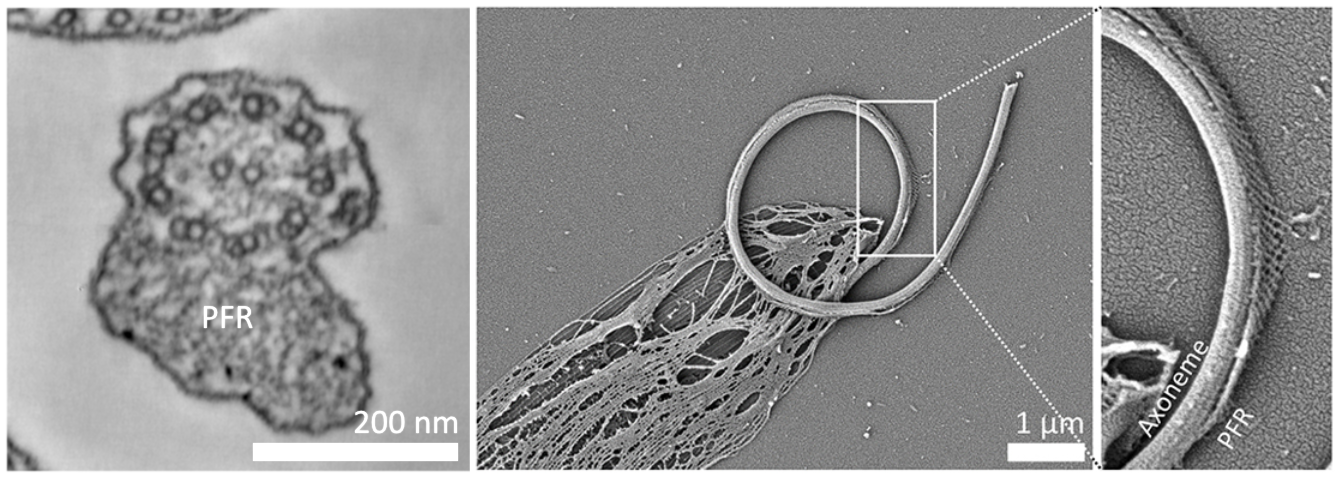
To illustrate, we highlight one task in biology below, requiring agents to analyze novel microscopy imagery.
Task:
refs/d465ab9a.png is an image of a crop from a thin section electron microscopy image of the Leishmania parasite. The Leishmania parasite swims using a single flagellum which has an asymmetric paraxial structure with a lattice-like internal structure, the PFR, as shown in the thin section electron microscopy image on the on the left. An axoneme mutation leads to curling up of the flagellum, as shown in the scanning electron microscopy of a detergent-extracted cell on the right, with the axoneme and PFR visible. The preferred bending plane of the flagellum is determind by the central pair microtubules. Dynein motor proteins on the axoneme doublets cause microtubule sliding which leads to flagellum bending. Based on these images, the dyneins on which set of doublets are over-active, leading to the curl?
A. Doublets 1, 2, 3, 8 and 9. B. Doublets 1, 2, 3 and 4. C. Doublets 3, 4, 5, 6, 7. D. Doublets 6, 7, 8, 9. E. Cannot be determined from the images.
Briefly justify your choice using the visible bend direction and axoneme geometry, then on the last line provide only the letter corresponding to the answer from the list.
Solution Rubric:
Criterion 1: Final dynein-set choice (30%) The submission ultimately selects option D, meaning the over-active dyneins are on doublets 6, 7, 8, and 9.
Criterion 2: Bend direction from PFR placement (25%) The submission explains that the paraflagellar rod lies adjacent to doublets 4 to 6 and appears on the outside of the curve, so the flagellum is bending away from the PFR and towards doublet 1.
Criterion 3: Candidate doublet sets narrowed correctly (20%) The submission narrows the dynein candidates to the two bend-compatible groups {1,2,3,4} and {6,7,8,9}, or an equivalent pair of alternatives, based on axoneme geometry.
Criterion 4: Minus-end-directed dynein reasoning (25%) The submission uses microtubule-sliding or minus-end-directed dynein reasoning to conclude that doublets 6, 7, 8, and 9 are the over-active set.
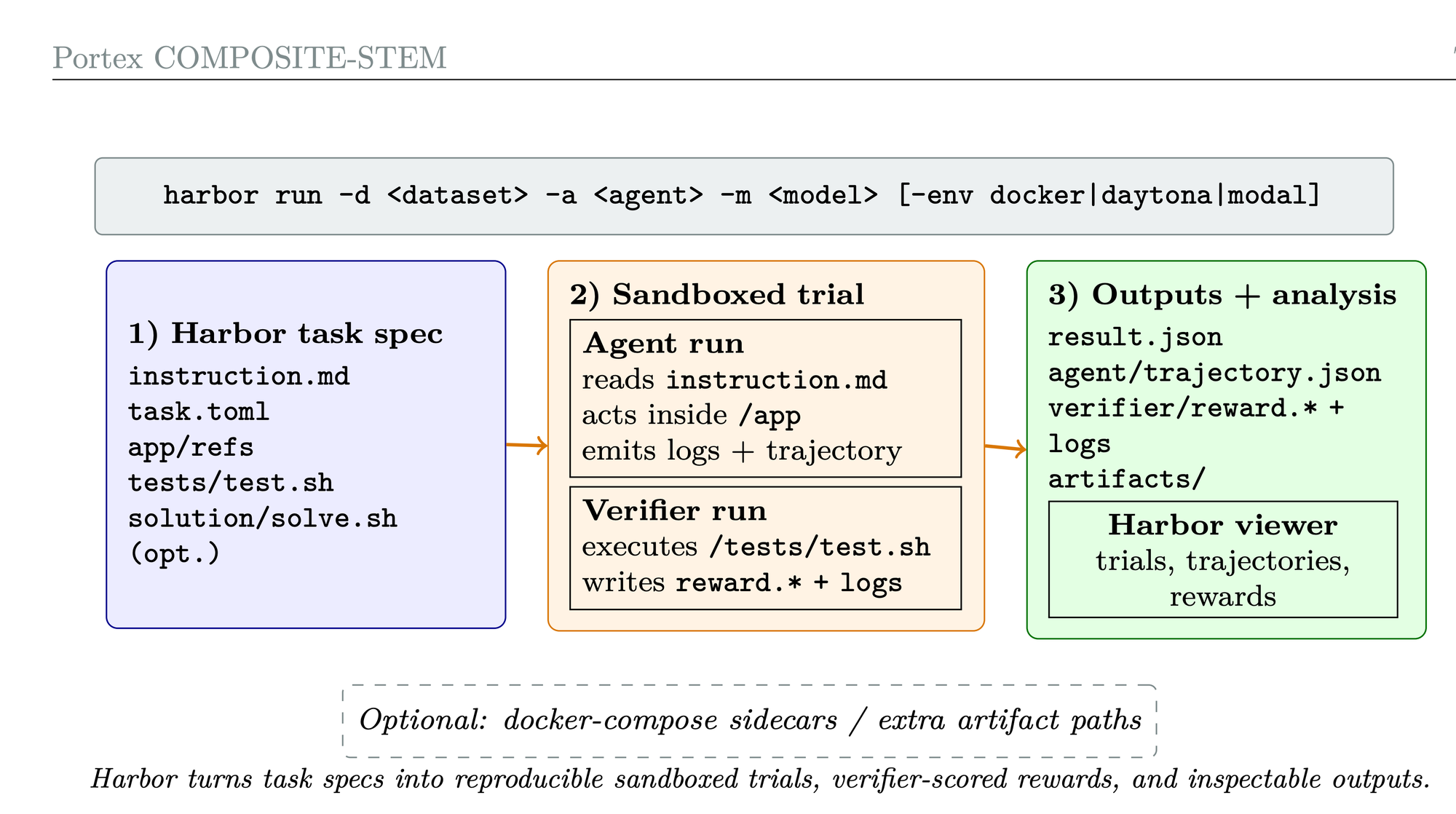
Evaluating Agent Performance using Harbor
Portex is integrated with Harbor, a framework for running agentic evaluations. Harbor allows for standardized evaluations in sandbox environments, promoting reproducibility and verbose tracing for agent trajectories, which is useful for error analysis. For evaluating models on COMPOSITE-STEM, we used an adapted version of the Terminus-2 harness with multimodal support (harness developed by the Terminal Bench team).
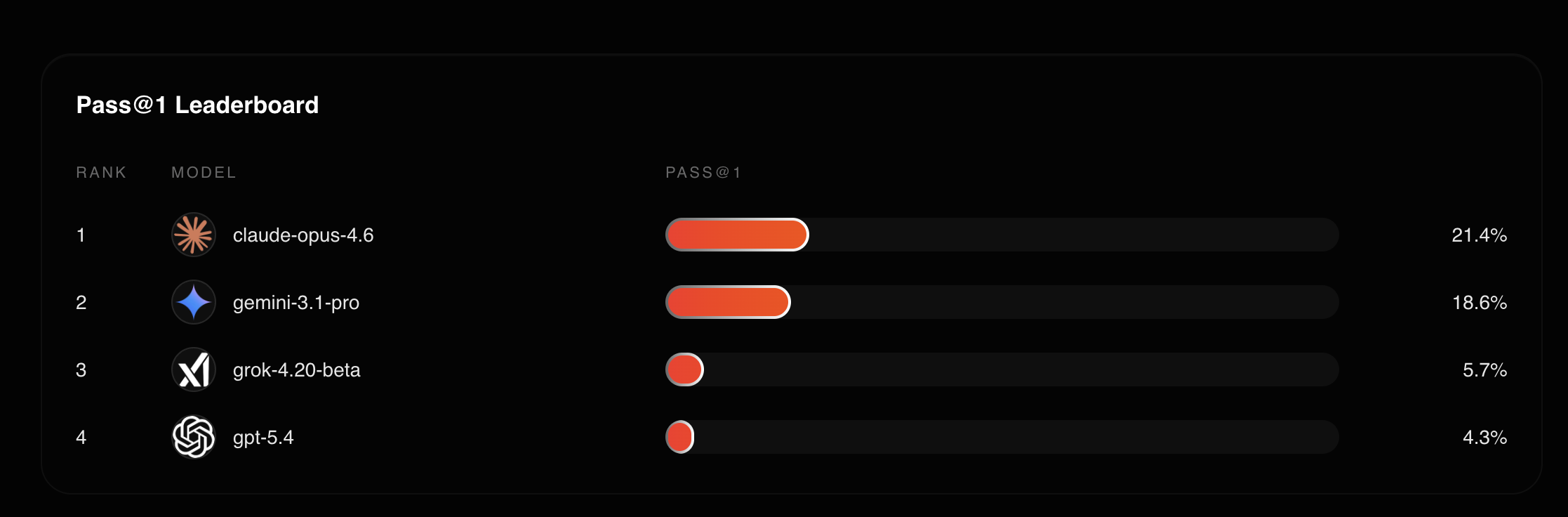
Among the 4 models we tested, Claude leads at 21.4%.
We conduct an extensive error analysis, noting that most failures can be attributed to solutions errors, that is, submitting a wrong solution. Submission errors (timeouts or failure to write an answer) account for the remaining errors. More details of this analysis are reported in the paper and provide more context on the deviation between model performance.
Conclusion
Agents may someday markedly improve researcher efficiency in professional and scientific settings, but evals are a critical step in building the trust needed to get there. By open sourcing the full task dataset and Harbor adapter, we hope this benchmark can be used as another robust and independent baseline to accompany the advancement of AI agents in the sciences.
Relevant links below to the COMPOSITE-STEM paper, dataset, and harbor adapter: