What Hugging Face Reveals About the Future of Model Fine-Tuning
The recent launch of OpenAI's gpt-oss series shows that performant open-weight models are abundant. Differentiation now comes from high-signal data. Hugging Face’s growth makes this visible at scale and points to a coming market for proprietary datasets for fine-tuning.
2025 has been a turning point for open-weight models
OpenAI’s recent release of its gpt-oss series marked a milestone for open-weight models. The two state-of-the-art (SOTA) and freely downloadable models (gpt-oss-120B and its smaller counterpart gpt-oss-20B) are well positioned for downstream use and even local deployment. They land just after the White House's AI Action Plan from July explicitly encouraged open-source and open-weight AI, and arrive in an ecosystem already primed by open-weight models like Meta's Llama series, Alibaba's Qwen, and Deepseek's R1 – all of which have accelerated post training and model fine-tuning.
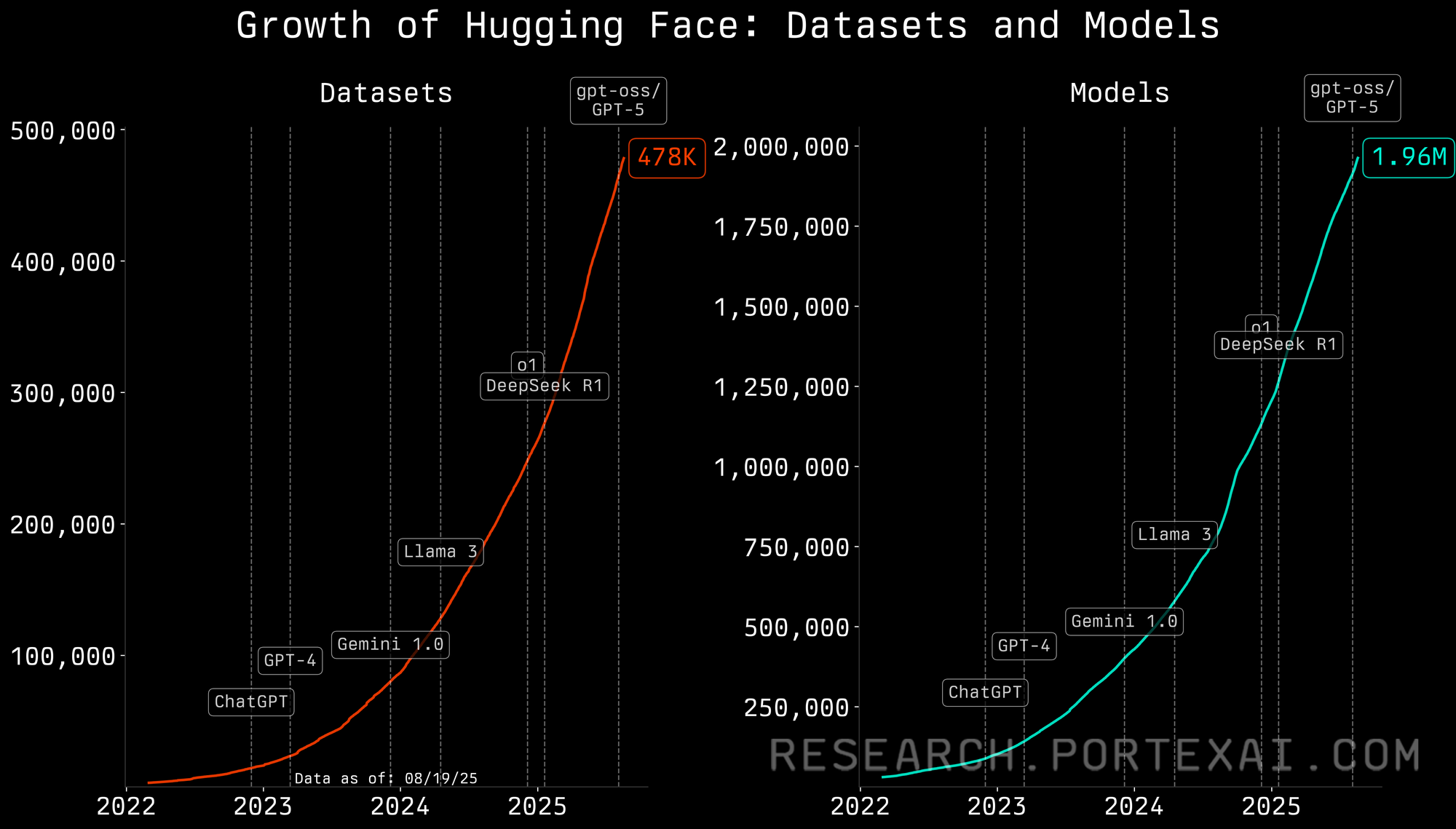
It’s no accident gpt-oss launched on Hugging Face, the GitHub-like platform that has become the heartbeat of open-source AI and the repository-bazaar where datasets, models, and fine-tunes are shared and deployed. We recently pulled the complete history of dataset and model uploads on Hugging Face to understand its growing importance in AI. The chart below shows just how big it’s become.
Hugging Face is now closing in on 2M public models and hosts over 450K user-uploaded datasets. Since 2022, there have been 54M downloads of these datasets and a staggering 1.5B total model downloads. This shows the bottleneck is no longer getting a competent base model; it is in assembling the right data and fine-tuning pipeline for specific tasks.
The golden age of fine-tuning
Much of the activity on Hugging Face is post-training models to fit a specific use case. The surface area for fine tuning is large, but practically speaking, teams combine a few families of methods:
Continued pre-training (CPT/DAPT): keep training a base model on domain-specific corpora to build the right vocabulary and style prior to task supervision.
Supervised fine-tuning (SFT / instruction tuning): learn from labeled demonstrations and reference answers.
Preference optimization: align model outputs to human or synthetic preferences, either with RL-based approaches (RLHF via PPO/GRPO with a learned reward model) or with offline methods that avoid online rollouts (e.g., DPO, ORPO, IPO, KTO).
Parameter-efficient tuning (PEFT): adapt large models without touching all weights, using LoRA/QLoRA (low-rank updates to existing layers), adapters (small added modules), or prompt/prefix tuning. These can be applied to SFT or preference-optimization stages to cut cost and speed iteration.
Historically, there has been some debate of the efficacy of fine tuning vs. simply using a large generalized model that can do it all. However, there is already some emerging evidence that is pointing to a world where small fine-tuned models can match or even outperform large models at the frontier.
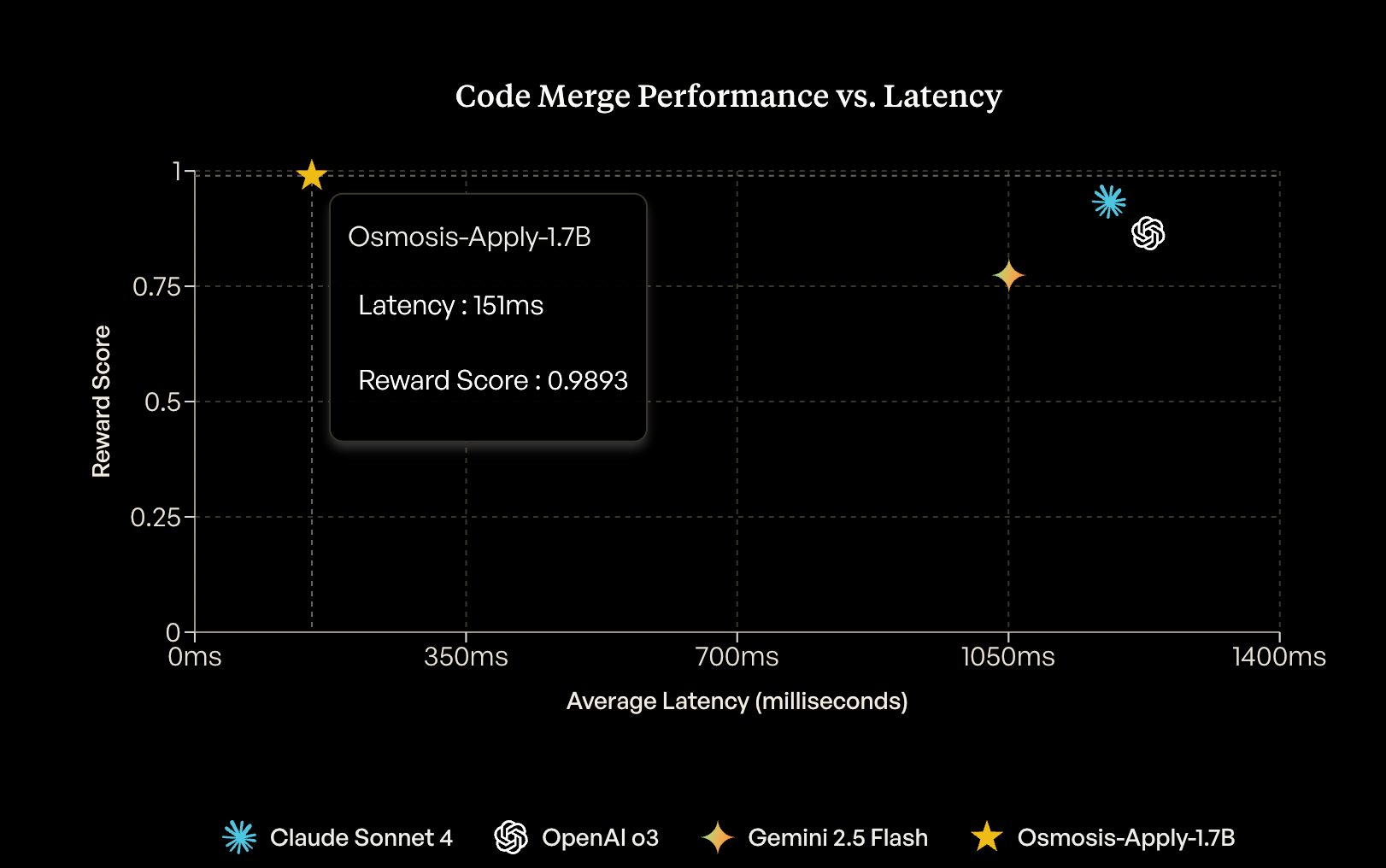
For example, Osmosis recently released its code merging model Osmosis-Apply-1.7B by fine-tuning Qwen3-1.7B on CommitPackFT(2 GB) using GRPO and a simple reward: 1 for perfect merge, 0.2 for format-near-miss, 0 otherwise.
With just about 100k well-curated examples, the model outperformed larger proprietary systems on a 10K-example validation for code merge while even running locally.This is remarkable – especially if we consider the often substantial cost savings and latency improvements when running specialized models relative to foundational models.
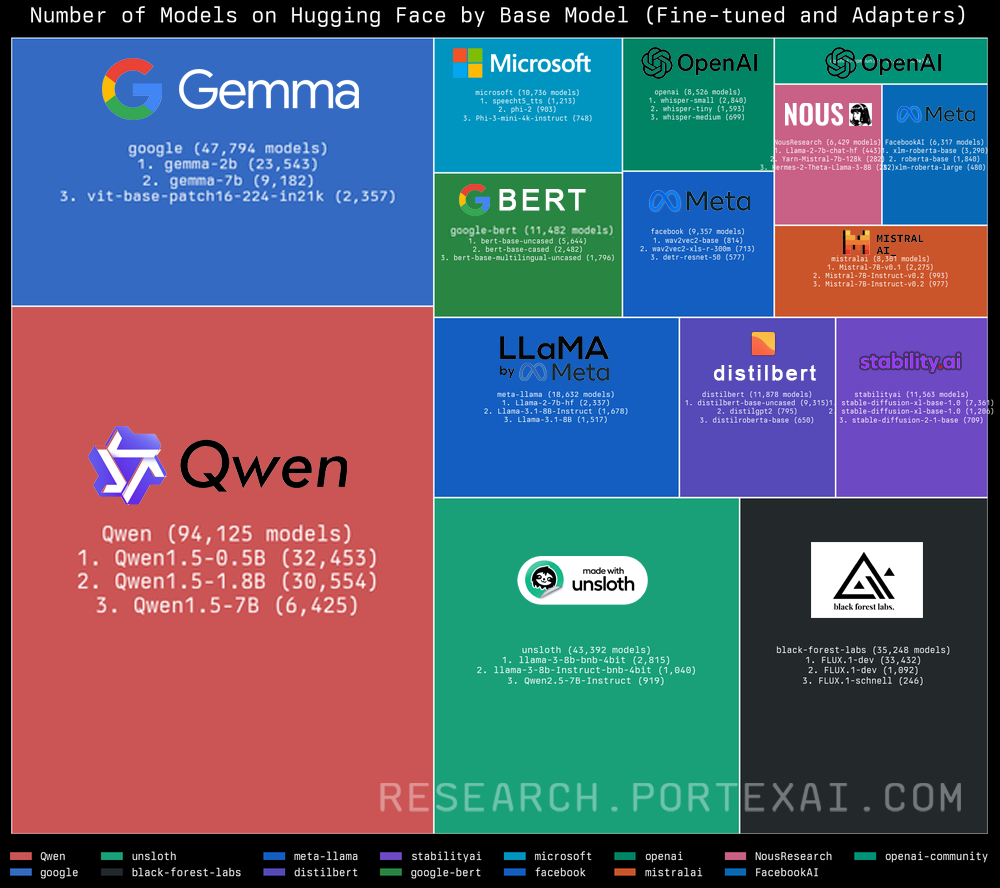
Hundreds of thousands of models have been fine-tuned and hosted on Hugging Face. After filtering model data from the Hugging Face hub API, we found that activity is clustering around a few base families (Llama, Qwen, Gemma, OpenAI's Whisper and gpt-oss) where specific versions of these base models that specialize in a local language or domain task stand out.
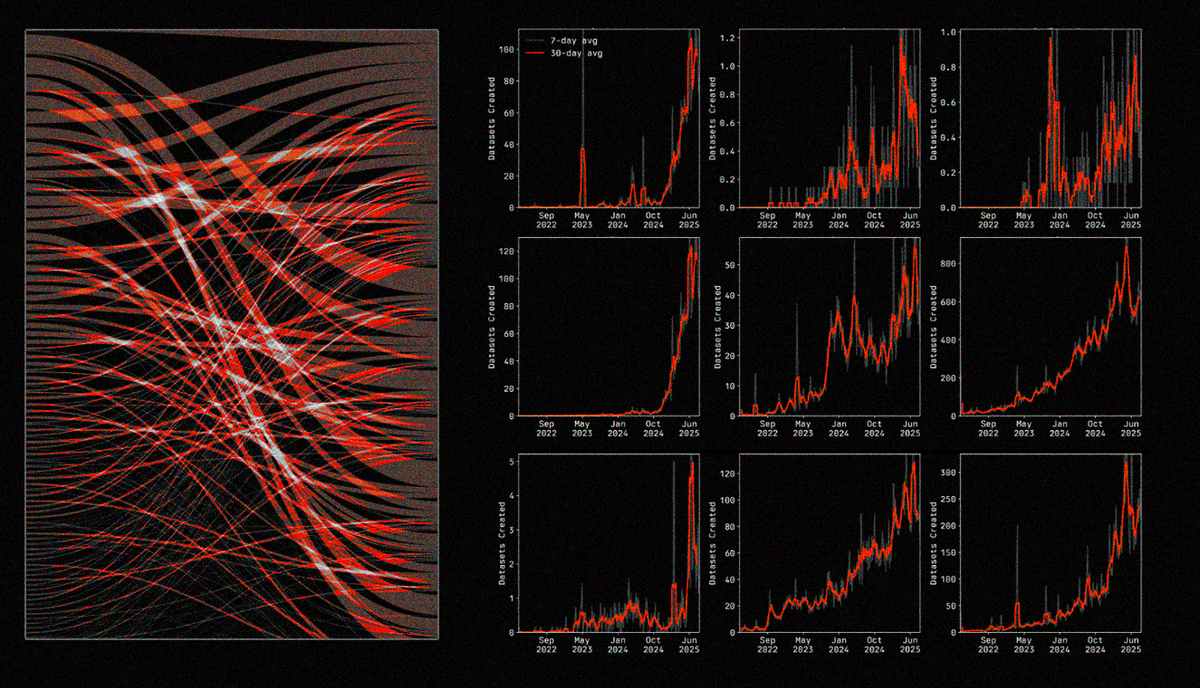
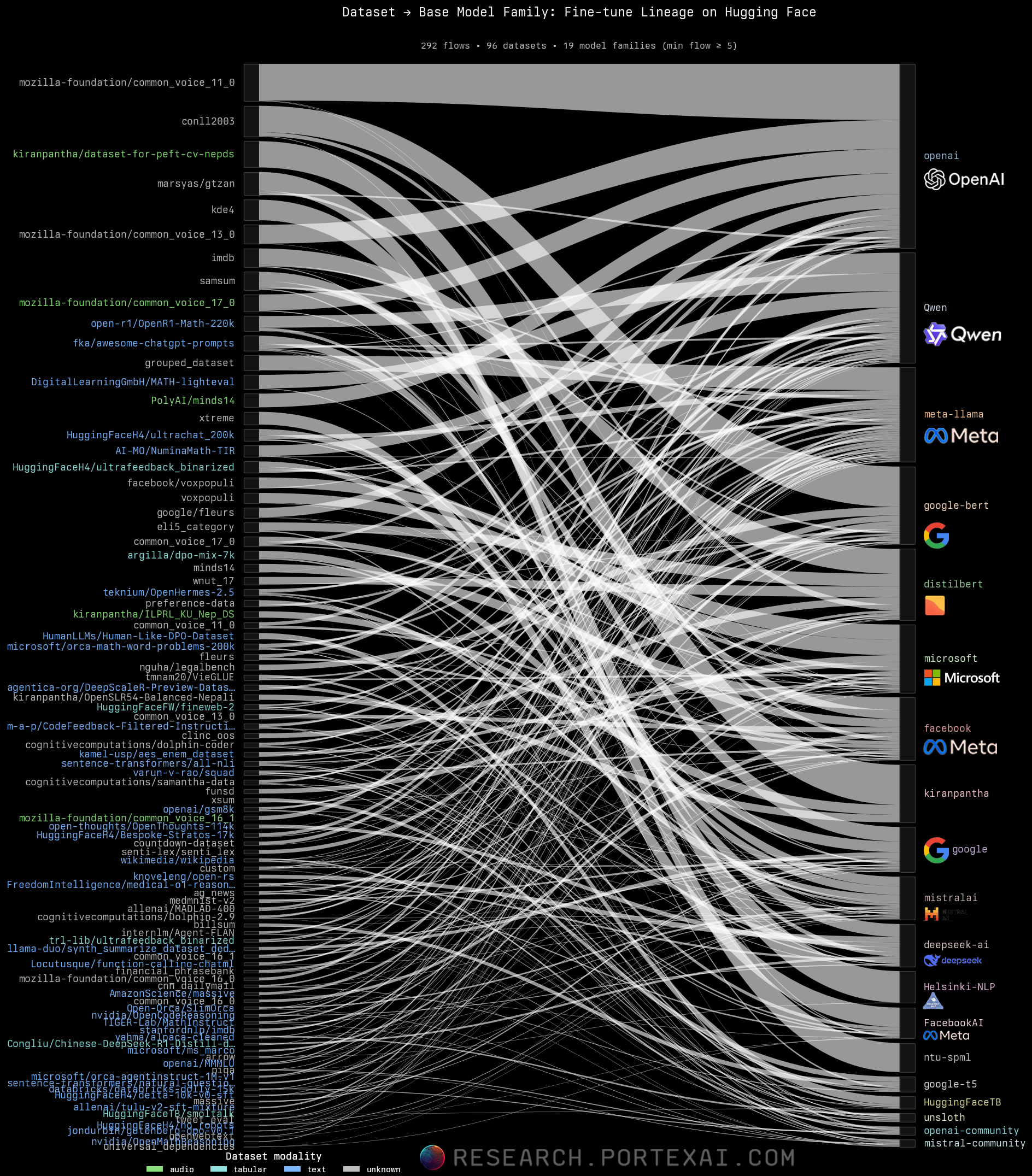
Tracing dataset‑to‑model lineage shows the depth of fine‑tuning on Hugging Face. The Sankey diagram below maps how hundreds of top datasets feed fine‑tunes and adapters for specific tasks. Major inputs include Mozilla's Common Voice, Wikipedia, and FineWeb, as well as more niche public datasets.
Many Hugging Face datasets flow into a handful of base models, which then branch into specialized variants. With multiple competent bases to choose from, data – not the base model – has become the true differentiator.
Data as the lasting differentiator
Investors and platforms are explicit: access to high-quality training data is a major competitive differentiator as inference, models, and software more broadly become commoditized. Andreessen Horowitz has urged U.S. policymakers to prioritize data access and called access to training data "the most important factor in determining global AI leadership".
Meta calls training data the “secret recipe” as facebook and all its platforms turn into vast data repositories. OpenAI's release of GPT-5's System Card makes only a passing comment about its training data with scant details. Even Hugging Face's CEO recently acknowledged the outsized importance of datasets on the platform and how its impact will eclipse that of models.
A clear distinction has emerged between fully “open source AI” and “open weights.” The latter releases only model weights, not the training data — a pattern that covers most popular open base models. Under the Open Source Initiative’s Open Source AI Definition (OSAID), true openness requires transparency across code, data, and training artifacts. By that standard, many high-profile “open” models are more accurately described as open-weight.
At the same time, web-scale text is scarcer than it appears. Work such as FineWeb shows that aggressive filtering and deduplication collapse Common Crawl-derived corpora by large factors while improving downstream performance. Availability of truly open, consented web text is tightening, which pushes value toward cleaner, rights-cleared, domain-specific corpora. Our scan of Hugging Face datasets reflects this shift: emerging gaps map directly to the data needs of post-training and fine-tuning amid these trends.
What Hugging Face shows about the supply and demand of AI training data
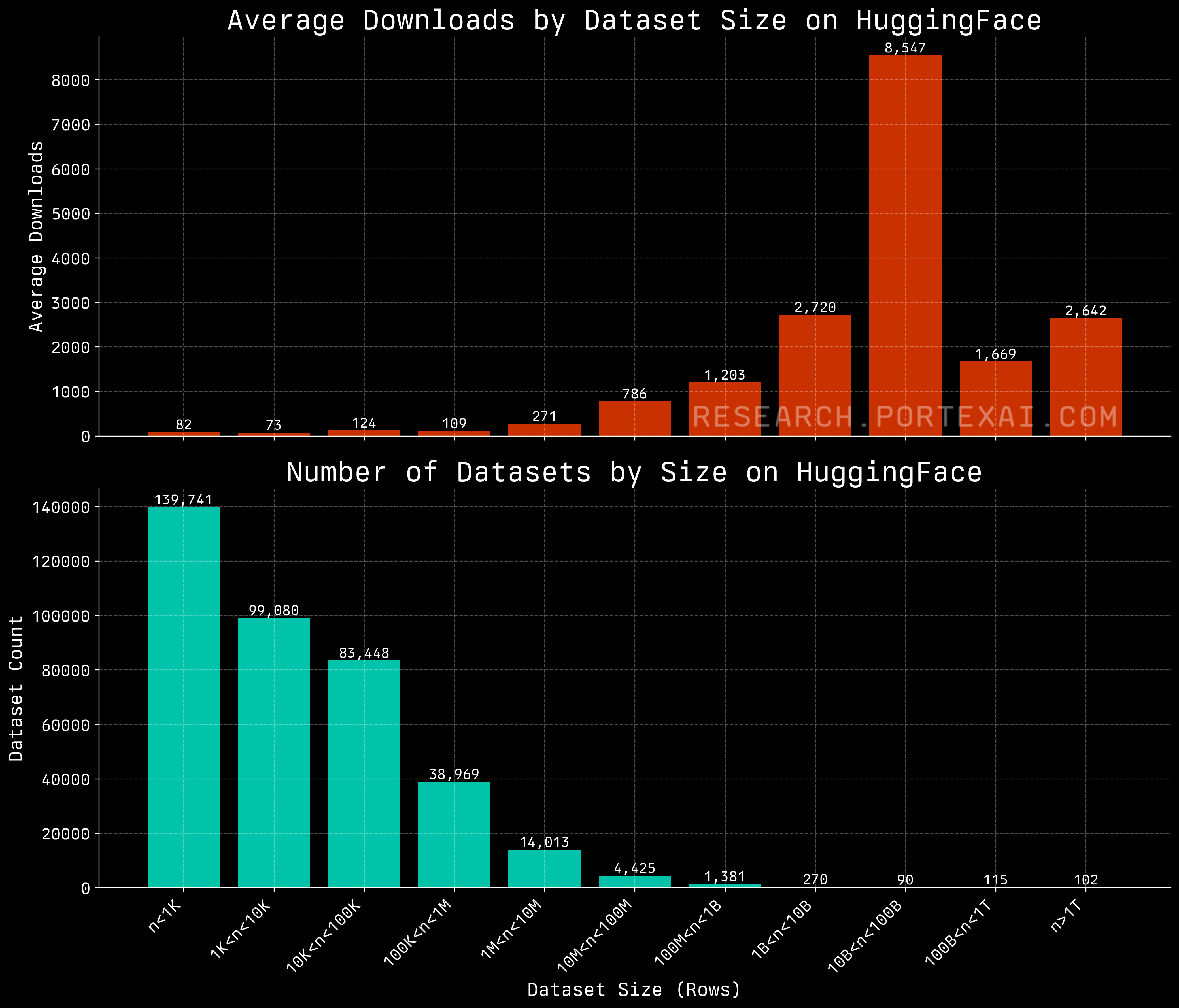
With nearly half a million datasets on the Hugging Face hub, what can we infer about the future of training data needs? One clear observation is that scale is still a major factor.
Larger datasets on Hugging Face receive many more downloads and interest on average than smaller ones. This is no surprise to us, as finding new large data sources can be highly impactful and has even sparked an active data licensing economy at the high end of the market (more on this in a future post).
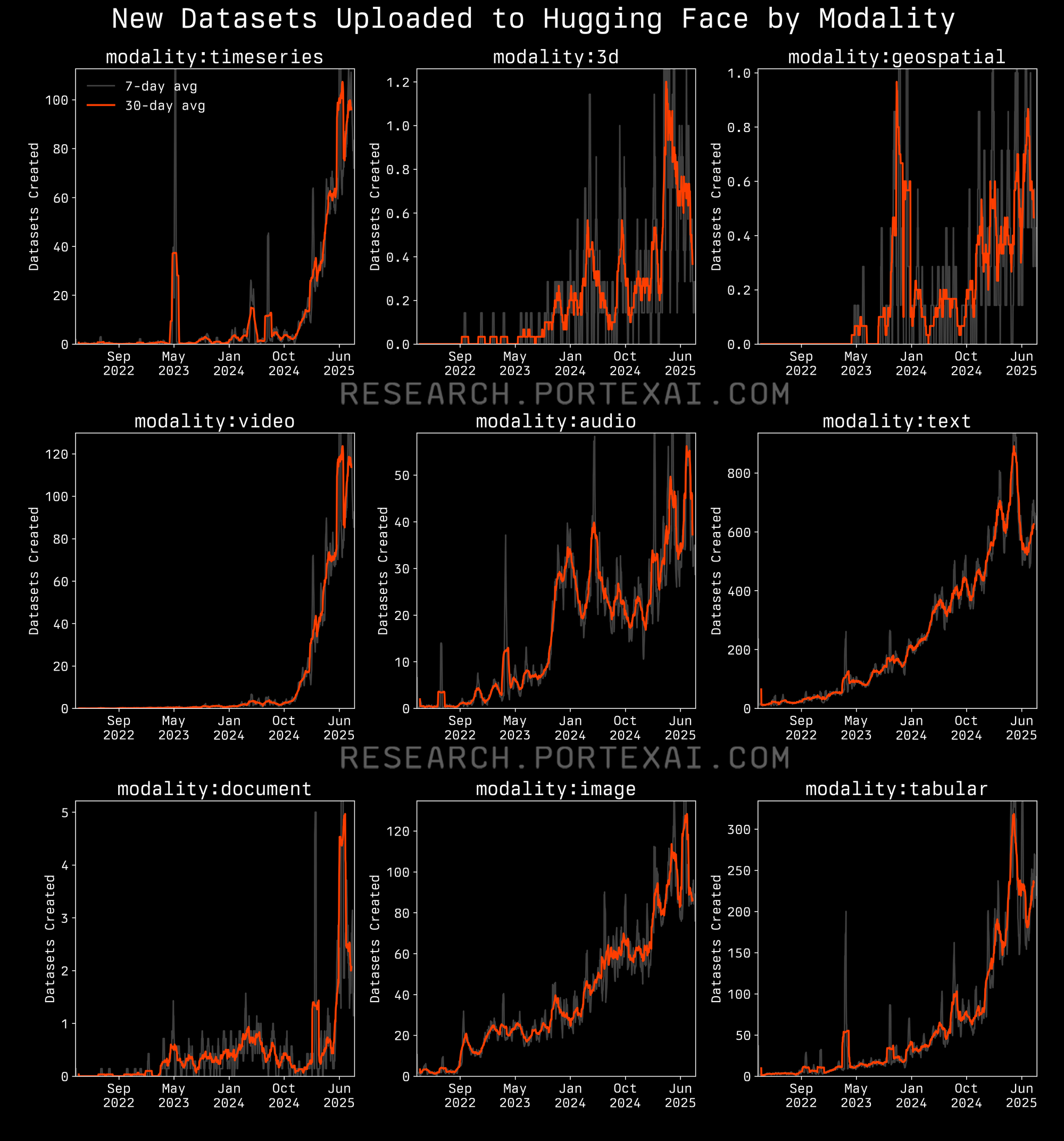
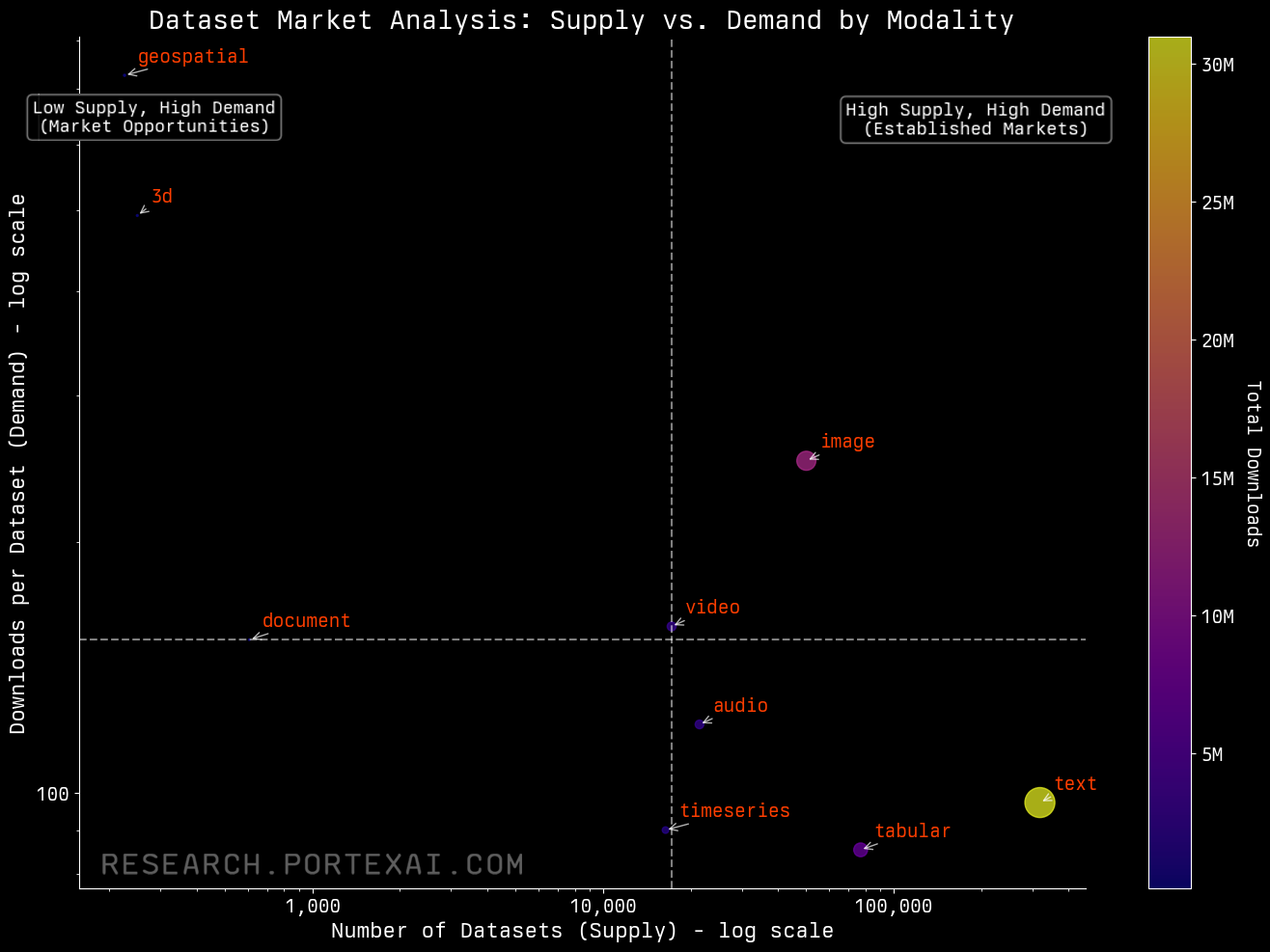
Focusing on datasets by modality shows where there are also opportunities. While text data is becoming fairly saturated, modalities like video, geospatial, 3D, and high-quality images show higher average downloads per dataset but fewer datasets on Hugging Face. Text and tabular data is easier to work with and fairly abundant and lower-yield per dataset. That signals undersupplied niches where specialized, licensed data can command price and attention. Already there has been an explosion in the number of video datasets uploaded to Hugging Face every day in the last year. At this time last year there were few video datasets being uploaded, now there are sometimes hundreds of new video datasets added per day.
Video and image data is interesting because it sits in a relatively low‑supply/high‑demand spot when compared against text data. AI research organization Epoch AI notes video in particular is one of the scarcest and most expensive modalities to collect and label, constrained by rights, privacy, and heavy storage/throughput costs.
As native multimodal models push toward embodiment, robotics, and physical real‑world tasks, demand is outpacing supply and is making rights‑clear, domain‑specific video prime for auctions and field‑exclusive licensing.
When pairing unique datasets with the rise of task-specific SFT and RLFT models on Hugging Face, we begin to see a clear loop:
Model builders identify a concrete task where small models can match performance and beat generalists on cost, latency, or both.
They acquire or construct high-signal datasets specific to that task.
They fine-tune efficiently using adapters or RL-style training with clear rewards.
Benchmarking and deployment.
Up until now, the importance of sourcing quality data may be underestimated or even under appreciated, but as more open weight SOTA models are released, we believe data will become the key determinant of success for specialized models.
The future of the AI data economy
Hugging Face proves that a collaborative approach to creating novel datasets is unquestionably propelling AI forward, especially with multimodal and specialized models. We fully expect this to continue as we approach the golden age of fine-tuning, when agents have access to highly specialized tools that can augment their capabilities. There are many factors pushing us in this direction: the need for faster inference, task specialization, and lower costs are just the most immediate catalysts on the horizon.
At PortexAI, we are accelerating this new era by making it simpler for novel datasets to be acquired. We believe that in order for truly proprietary and highly specialized datasets to be surfaced, their owners need to be compensated fairly for the time, effort, and resources used to create them. These datasets can be combined and oversampled alongside open datasets to push the boundaries of what's possible. We love what Hugging Face has built and hope to become its counterpart for paid datasets with the Portex Datalab, which is already helping builders find these highly-curated datasets.
The link has been copied!
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.