Today we’re excited to share Portex’s first research paper based on a large dataset of smart contract bytecode. Our paper, Reputation Oracles: Determining Smart Contract Reputability via Transfer Learning, addresses a critical question: is it possible to programmatically identify malicious smart contracts solely on the basis of their decompiled bytcode?
Our findings are promising, with our model achieving a remarkable 94% accuracy in classifying unseen smart contracts as malicious or reputable. This research paves the way for further efforts to analyze decompiled smart contract bytecode—one of the least-explored types of onchain data—for classifying crypto primitives and fostering trust in decentralized applications.
Background
Building on Bitcoin’s seminal innovations, Ethereum’s 2015 launch brought general-purpose, Turing-complete smart contracts to blockchains, enabling not just the transfer of value over the internet without intermediaries, but also the execution of arbitrary pieces of code in a stateful environment—allowing all sorts of decentralized applications to be built. While open-source, permissionless platforms like Ethereum offer numerous benefits like composability and censorship resistance, their open and neutral nature inevitably allows for the co-existence of contracts written by malicious actors. Therefore, the ability to differentiate between trustworthy and malicious programs at scale is a crucial step in advancing the adoption of onchain applications.
Methodology
To construct a high-quality training dataset for our machine learning model, we started with an in-house data collection process that enabled us to identify and compile a list of smart contract deployers with established reputations. The “deployer” is the Ethereum address that creates a smart contract and commits its code to the Ethereum blockchain. Despite the inherent challenges in quantifying a subjective concept like reputation, we applied a rigorous vetting process and a due diligence questionnaire, informed by our collective expertise, to ensure the credibility of these projects. Afterwards, we gathered a representative set of known malicious contracts from Forta and other public sources.
For onchain data, we used the Cryo ETL (Extract, Transform, Load) to collect the complete set of contract bytecodes deployed by these verified deployer addresses. Cryo is a high-performance, Rust-based ETL that offers a wide range of structured onchain data outputs, including contract bytecode.
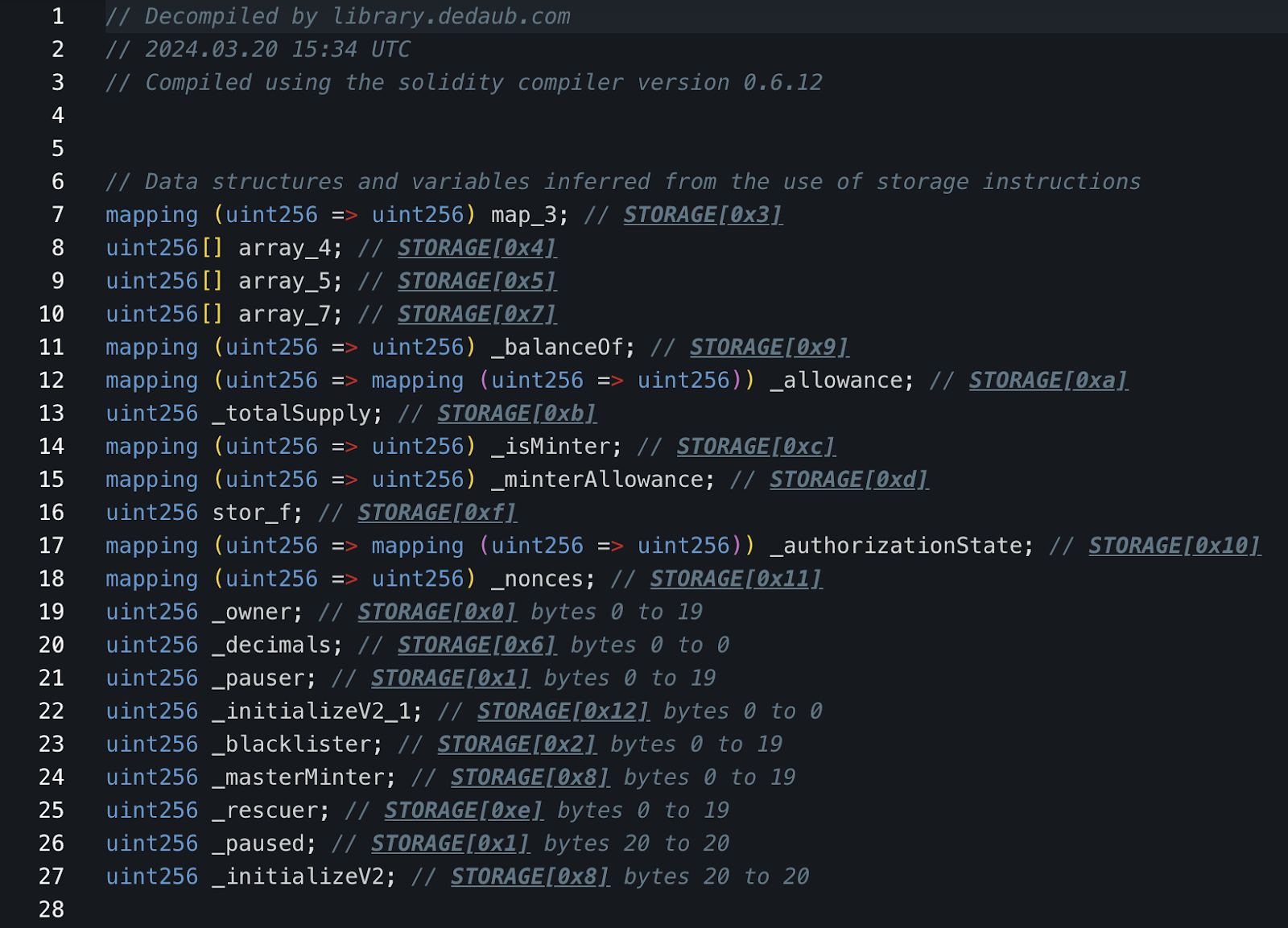
To get the contracts in pseudo-Solidity format we used Debaub's bytecode decompiler, as shown below (decompiled bytecode is the reverse-engineered version of the compiled machine code back into a human-readable form that is closer to its source code).
Decompiled bytecode from Debaub
Armed with datasets representing both “good” and “bad” applications, we turned to the classification task and the training of our model.
Machine Learning as a Reputation Oracle
Our model operates on the principle that deep learning can identify patterns within decompiled bytecode. To this end, we utilized LongCoder (2023), a Long-Range Pre-trained Language Model for Code Completion. It shines at processing extensive code context, suitable for analyzing long smart contracts.
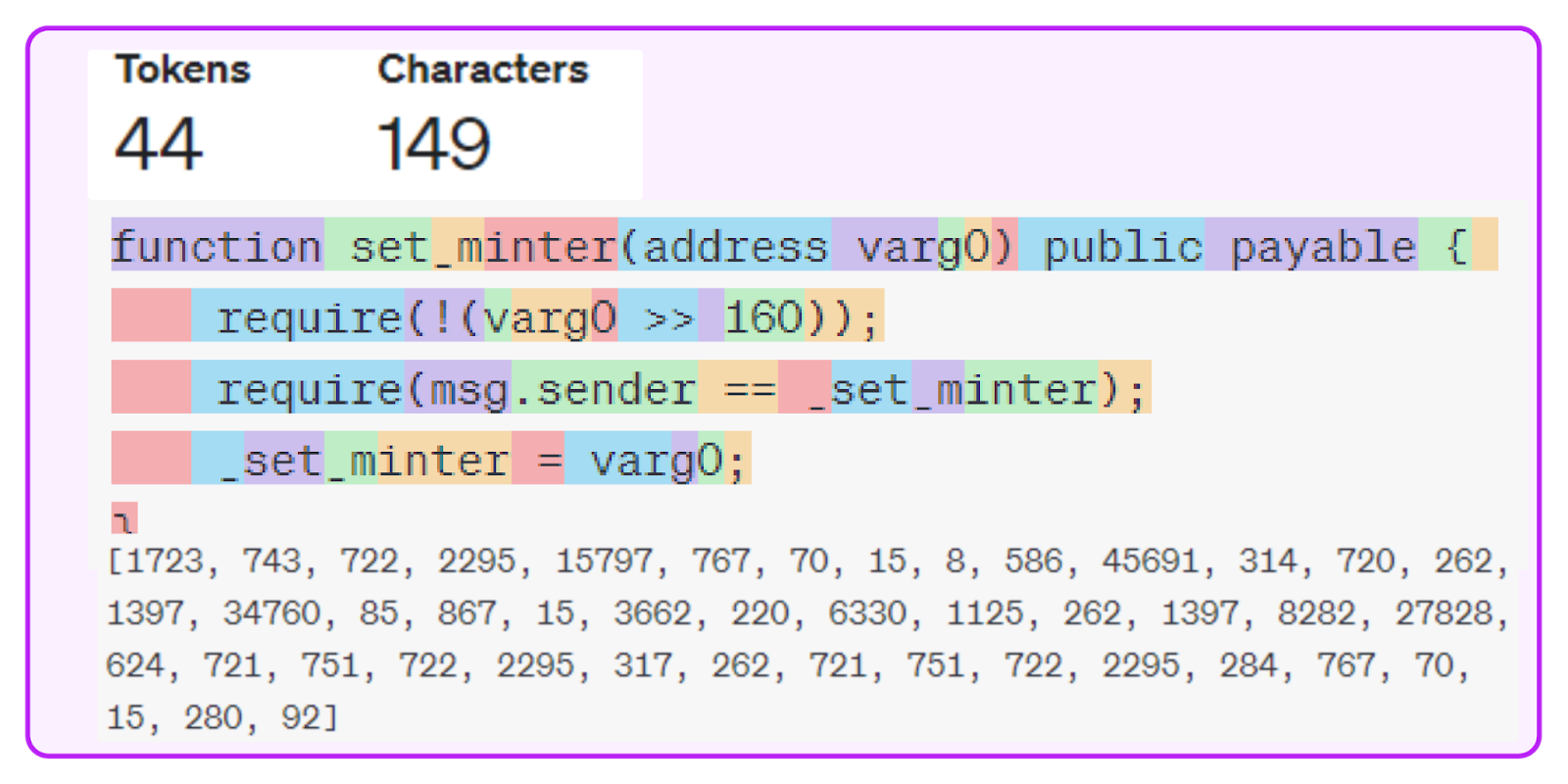
LongCoder operates by initially tokenizing the input text from the decompiled bytecode. This process involves breaking down the code into smaller units called tokens, which can be thought of as the fundamental elements of language, similar to words and phrases in a sentence. The diagram below illustrates the process by which LongCoder tokenizes a function.
Using LongCoder to tokenize a function
Once the code is tokenized, LongCoder converts these tokens into numerical vectors known as embeddings. These initial embeddings capture the semantic meaning of each token, providing a mathematical representation that the computer can process.
Following the creation of these embeddings, LongCoder takes these initial embeddings and adjusts them to encode the contextual relationships and syntactic structure of the text. This results in a more sophisticated contextual representation of the text, capturing the deeper meaning and relationships within the decompiled smart contract source code.
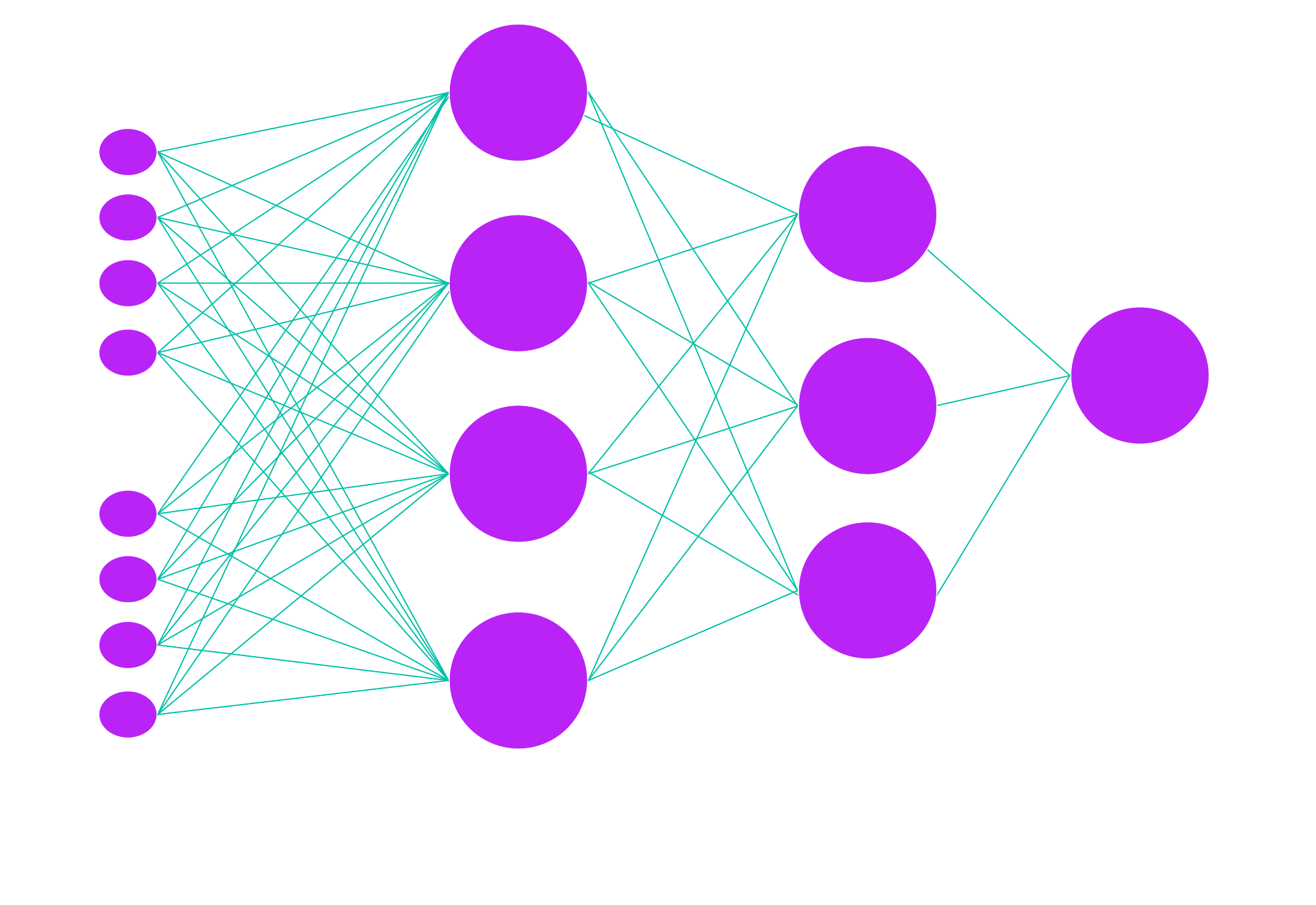
The final step of our model involves feeding these refined embeddings into a neural network that we trained to classify smart contracts as either reputable or malicious. The neural network uses the information encoded in the embeddings to make this determination, based on patterns it has learned for analyzing a large dataset of decompiled smart contracts.
Example of a Feed Forward Neural Network
Results
The model demonstrates promising results, accurately identifying 94% of the contracts evaluated in the test set. We believe the success of the model likely stems from its ability to discern contextual clues within decompiled bytecode. For instance, a common fraudulent tactic involves a hacker creating a sweeper function designed to iterate over all assets in a user's wallet and transfer all of their funds to another account, masquerading amongst legitimate operations. Genuine projects rarely, if ever, require such functionality. We posit that the model is adept at detecting these irregular, anomalous code patterns. While superficial aspects of a function can be altered like a human-readable name, the input variables and core components remain constant, enabling the model to recognize these telltale signs of malicious intent.
Limitations
Our approach is not without limitations that future research must address. Notably, our method is not a cure-all; there are always going to be instances where ostensibly "harmless" contracts are repurposed for nefarious activities. For instance, a contract designed to mint new tokens, a critical function for legitimate projects like stablecoins, may be exploited for malevolent schemes where bad actors may covertly allocate tokens to themselves.
Additionally, the identification of "edge cases" involving malicious contracts necessitates the collection of more comprehensive data. This is also true for keeping pace with "adversarial" tactics, as malicious parties may alter their methods to evade detection. But this is ultimately a game of cat and mouse, and enhancing our model and expanding our dataset are important steps toward mitigating these issues.
Implications & Future Work
The high accuracy observed in our classification task demonstrates that decompiled bytecode contains rich information that is detectable in machine learning models. This discovery opens the door to a wider range of machine learning applications in bytecode analysis, including the development of more sophisticated classification models, predictive analytics for contract behavior, and possibly, the creation of automated development tools to enhance the clarity, safety, and usefulness of onchain applications. We believe a robust reputation system is vital for the success of onchain applications to see mass adoption, and our research lays the groundwork for users and developers to engage crypto primitives with greater assurance.
Be sure to check out the paper in its entirety on SSRN here and subscribe to receive updates on future research. Also, feel free to reach out to the Portex team on X (@PortexAI) for any feedback and discussion.
The link has been copied!
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Your link has expired. Please request a new one.
Great! You've successfully signed up.
Great! You've successfully signed up.
Welcome back! You've successfully signed in.
Success! You now have access to additional content.