


Sep 24, 2025
9 min read
Data has been called the world’s most valuable resource and “unreasonably effective” at modeling the world around us, yet, the economics governing AI data acquisition have remained largely unchanged. Up until recently, AI training data was either taken as a given (through canonical datasets like ImageNet or Common Crawl), or created through labor-intensive but routine labeling assignments. Many of the headlines covering the AI investment race in the last few years have focused on compute and hardware rather than data, but this is rapidly changing.
Access to novel training data is increasingly recognized as the lasting differentiator in AI, and labs are paying top dollar for quality data. Researchers from UIUC recently noted that the total revenue of the data labeling industry jumped an incredible 88x from 2023 to 2024 with the majority of (marginal) training cost now shifting to data. Publicly-traded companies like Reddit, Shutterstock, Yelp, and others are building out formidable data businesses on the foundations of multimillion dollar annual data licensing deals struck with top AI labs.
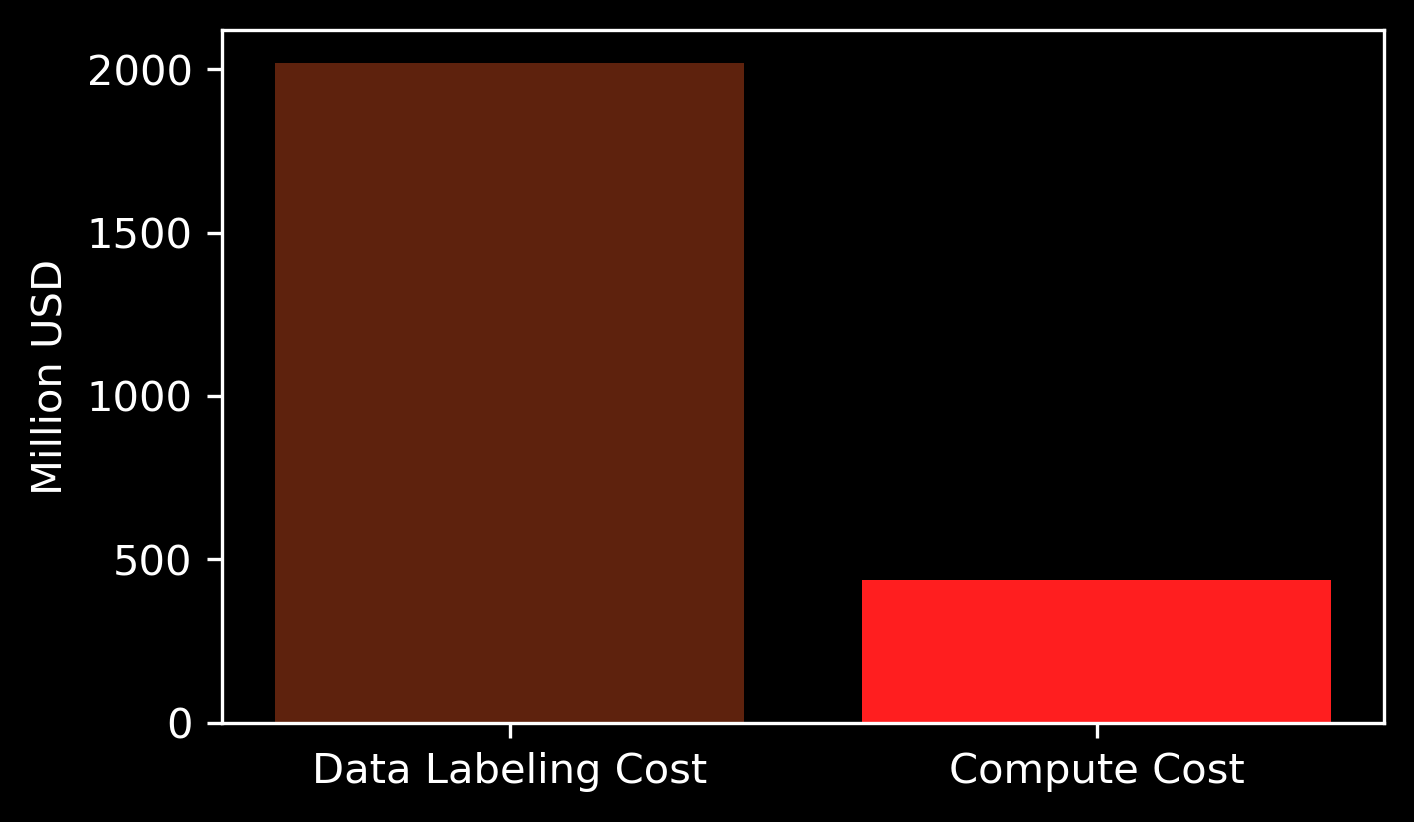
Source: Human Data is (Probably) More Expensive Than Compute for Training Frontier LLMs
This fast developing data investment race is pushing the limits of old structures, demanding new approaches to valuing, managing, and incentivizing the creation of frontier AI data.
Mapping the new AI data economy
Today's gen AI models are not just feats of algorithmic ingenuity (in fact, the original ideas behind artificial neural networks date to the 1940s). And they are not just products of mass levels of compute, either. Scaling today relies on vast corpora of human-generated data that are orders of magnitude larger than training datasets used just a few years ago.
While much of this data has historically been scraped from the open web, an insatiable demand for new data—combined with data owners waking up to the value of their assets—has left labs up against a "data wall" to keep scaling. With the public stock of data possibly being exhausted in the next few years, labs are increasingly turning to external datasets to fill the gap. OpenAI has reportedly committed $1B this year to data-related spend to improve its models (with plans to increase to $8B by 2030)—and this is just a single lab (for context, the entire market for alternative "alt data” in quant finance is estimated to be somewhere around $2.5B).
This AI data economy is largely formalizing in two areas today: data licensing deals between labs and data/content owners, and the sourcing of experts whose knowledge and datasets can align state-of-the-art models in high-skilled domains like mathematics, medicine, law, and finance. Labs crave data in these two areas given the extent to which it can be a performance multiplier, especially when considering performance per dollar spent on a given model.
The AI Data Licensing Boom
Data licensing for AI has grown considerably since 2022. The timeline below shows a few of the major announced deals and their respective sector.

Sources: PortexAI Research & Public Disclosures
While many deal amounts have gone unreported, some of the largest deals include Reddit and OpenAI/Google (both reportedly around $60M annually) and News Corp and OpenAI ($250M).

Source: Reddit Q2 2024 Letter to Shareholders
Publicly traded companies such as Reddit and Shutterstock are increasingly calling out data and content licensing as a growing line item: we estimate ~10% of Reddit's revenue comes from data licensing today while Shutterstock’s $3.7B merger with Getty underscores the strategic importance of the two companies’ data and content businesses amid rising demand from AI labs. According to some reports, Reddit is back at the negotiating table vying for an even more lucrative deal for its data with Google, OpenAI, and others.

Source: Shutterstock investor presentation, February 21, 2024
Many other companies are getting in on the action across media, enterprise, and news—even AI companies themselves. A recent report from the tech publication The Information noted that Anysphere, the company behind the popular AI coding assistant Cursor, has started preliminary conversations with OpenAI and xAI to license its data on how millions of software engineers use Cursor to write code. This data has already been used by Cursor itself to enhance its Tab model using online RL methods.
Data Labeling & Expert RL
Data quality has always been a decisive factor in AI, but newer, more capable models and agentic use cases are reshaping the data labeling industry. Meta's $14B investment into AI data labeling stalwart ScaleAI this past June highlights the growing needs for specialized data. Unsurprisingly, Meta's AI team has publicly acknowledged the value of differentiated training data, even calling it "the secret recipe and the sauce" that goes into building state of the art models. In a sign of the fierce competition and secrecy surrounding training data, OpenAI and other labs dropped ScaleAI soon after Meta's just-under-50% investment in the company.
With the rise of reasoning models and new reinforcement learning-based approaches, focus has quickly shifted to expert-curated datasets and annotations. Companies like Mercor, SurgeAI, Invisible Technologies, and Turing have benefited greatly. The creation of RL environments which are effectively simulated computer use scenarios, has stimulated demand for expert feedback in specific agentic use cases. These datasets are simultaneously high signal and hard to collect, which has created a considerable opportunity for data providers in this segment.
The changing nature of the web
High demand is driving AI labs to seek out external data, but there are other forces pushing labs to pay for high-quality data. With data licensing deals measured in the tens, sometimes hundreds of millions of dollars, data owners are closely monitoring for commercial-scale use of unwanted crawlers. Allegations of copyright infringement and breaches of terms of service have resulted in high-profile lawsuits between AI labs and content owners.
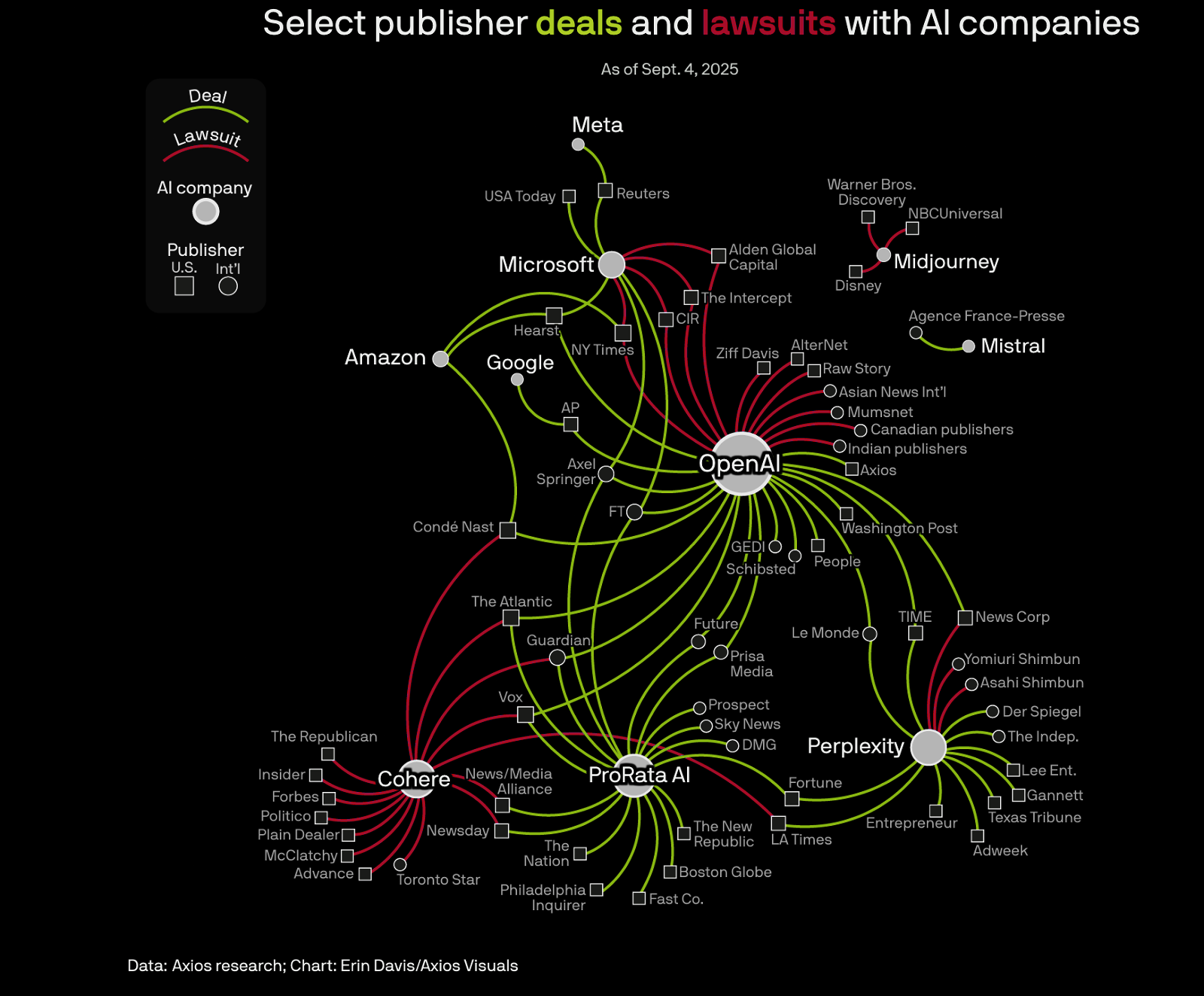
Source: Axios
While many of these cases are ongoing, some have already settled, with Anthropic notably settling for $1.5B with a group of authors and publishers earlier this month. This settlement marked the single largest payout in the history of U.S. copyright cases with Anthropic agreeing to pay $3,000 per work to 500,000 authors.
Putting aside copyrighted content, the "open web" itself is becoming much less open due to a never-ending swarm of AI crawlers and bots. Last year, Cloudflare introduced a product ominously called the "AI Labyrinth" that slows down, confuses, and ultimately wastes the resources of AI Crawlers and other bots when they don’t respect “no crawl” rules. Open datasets like Common Crawl are also shrinking as more websites opt out. The indexing initiative's latest release (Sep 2025) captured roughly 2.39 billion pages vs 3.15 billion pages just three years ago in Sep/Oct 2022—about a 24% decline.
With demand higher than ever and the open web closing due to a crisis of consent, the need for new incentives is acute.
New (AI) models, old (incentive) models
Behind many of the data deals today is a data brokerage market that has chronic shortcomings. For starters, much of the data being sold belongs to individuals who generally see no upside from these transactions. Deals are struck behind closed doors, with limited transparency around sale prices or how the data is ultimately used. Brokers typically license the same data to multiple buyers, preserving their own position as gatekeepers while sidelining those individuals who originally produced the data.
Moreover, pricing mechanisms remain opaque, brokers often negotiate bespoke contracts on a client-by-client basis, offering minimal public price discovery—hurting data owners. Regulations such as GDPR and the Consumer Privacy Act have attempted to implement more disclosures and opt-out procedures, yet the data brokerage industry continues to operate largely as a black box.
Traditional data brokers are simply not structured to service the AI buyer archetype, which demands flexible pricing structures, much faster sales cycles, better data delivery and, most importantly, more novel datasets. One of the most important areas for market transparency is valuation. There has been little work done on data valuation today, but it is desperately needed.
A New Approach to Data Valuation
The value of any good is ultimately determined by how much someone else is willing to pay it. This is particularly difficult for data under traditional data brokerage, as it operates as an opaque private market. Like many assets in the past, moving data from private to public markets provides the best path to change its valuation dynamics. Much like fine art, the nature of data as an asset is non-fungible, which entails leveraging unique auction mechanisms.
With the Portex Datalab, we've built what we believe to be the first genuine implementation of auctions for datasets. The opportunity and design space here is huge, and there is a large body of research we are using as inspiration as our auction design evolves. Beyond the traditional English auction, alternative mechanisms like Vickrey and Dutch auctions can be used to more adequately price unique datasets. These mechanisms are particularly useful for data as they maximize real pricing while minimizing mispricing phenomena like winner’s curse.
Nevertheless, just like with public markets, it’s important to have a foundation for valuing datasets using fundamentals and first principles. There is interesting literature inspiring our efforts here as well. Zillow famously pioneered the "Zestimate", a near real-time valuation for houses that were not just on the market but crucially off market as well. Despite its early flaws and limitations, it gave home owners and buyers a starting point (and Zillow a powerful platform for analyzing the US housing market).
What would a Zestimate for data look like today? As it turns out, there are actually a few things in common. Like houses, data is also non-fungible (non alike), while ascertaining quality is a crucial variable. But information asymmetries are also high, necessitating the role of local housing market experts and home inspectors. Size and newness are of course also important, as is uniqueness. The modality and use case(s) are also important.
Although there's not much data out there yet on data deals, we've been experimenting with providing a baseline using fundamental factors, which at the very least could be used as a signal for pricing floors. Many of the data owners we've spoken with don't quite know where to start with valuing their data, so our baseline can provide a helpful reserve price.
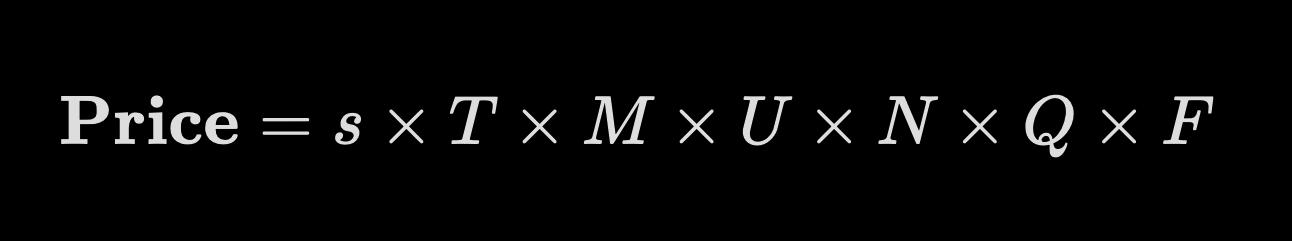
Where each variable is defined below.
- s — Usable token count after deduplication & cleansing
- Typical range: 10K–10B+
- Diagnostic questions: “How many unique, clean tokens/rows remain once noisy duplicates and invalid records are removed?” Token equivalents for images, video, and audio are computed.
- T — Baseline $0.001 per token
- Typical range: Constant
- Diagnostic questions: Assumed baseline for text data on the web from Reddit-Google data licensing deal $60M size of the deal divided by 600B estimated total tokens.
- M — Modality multiplier (text = 1; text+code = 1.1–1.4; audio = 5–10; video = 10–20)
- Typical range: 1–20
- Diagnostic questions: “Does the data embed higher-value media such as labeled images, audio, or video?”
- U — Use-case scaler (accounts for domains with higher demand or high-value tasks; 0.1 = weak/unclear buyer or use case)
- Typical range: 0.1–1
- Diagnostic questions: “How is this dataset going to be used? Is there a clear buyer in mind? Is this a domain with a dearth of training data?”
- N — Uniqueness/commonality scaler (i.e. replication cost)
- Typical range: 0.01–10
- Diagnostic questions: “How costly or legally tricky would it be for someone else to recreate this set?”
- Q — Quality & compliance factor (noise, label accuracy, privacy risk, legal provenance)
- Typical range: 0.1–1
- Diagnostic questions: “Has the dataset been audited for PII, and are labels ≥ 95% accurate? Has an expert reviewed the validity/plausibility of the data?”
- F — Freshness/decay factor (news/financial data decays faster; educational material is more timeless)
- Typical range: 0–1
- Diagnostic questions: “How fast does stale data hurt performance in this use case?”
This is just a starting point, but something that already resonates with our data sellers. We believe this is one of the most impactful areas to solve in the data economy today, because at its very essence, the challenge builders face with data today is an incentives one. As such, it is a solvable challenge if better alignment primitives are put in place that should, simultaneously, fairly reward data producers and expand the supply available to data consumers. We have put a lot of thought into building these primitives, and we’re excited to share more about how they are being integrated into Asymmetry0, our core market engine.
Conclusion
While demand for data has never been higher, supply remains fragmented, unstructured, and often contested. Markets are remarkable at allocating scarce resources. They coordinate supply and demand and reveal price signals that help participants— and society—understand what is valuable. The data economy deserves the same foundation, and it’s worth building.